
타임라인은 일정 양의 데이터만을 로딩하고 사용자가 +read more버튼을 클릭하면 새로운 데이터를 끝에 추가로 로딩하는 방식으로 동작한다. 각각의 데이터들은 날짜별로 분류되어 있으며 최신 순으로 정렬되어있다.
내가 만들 타임라인의 구성은 다음과 같다.
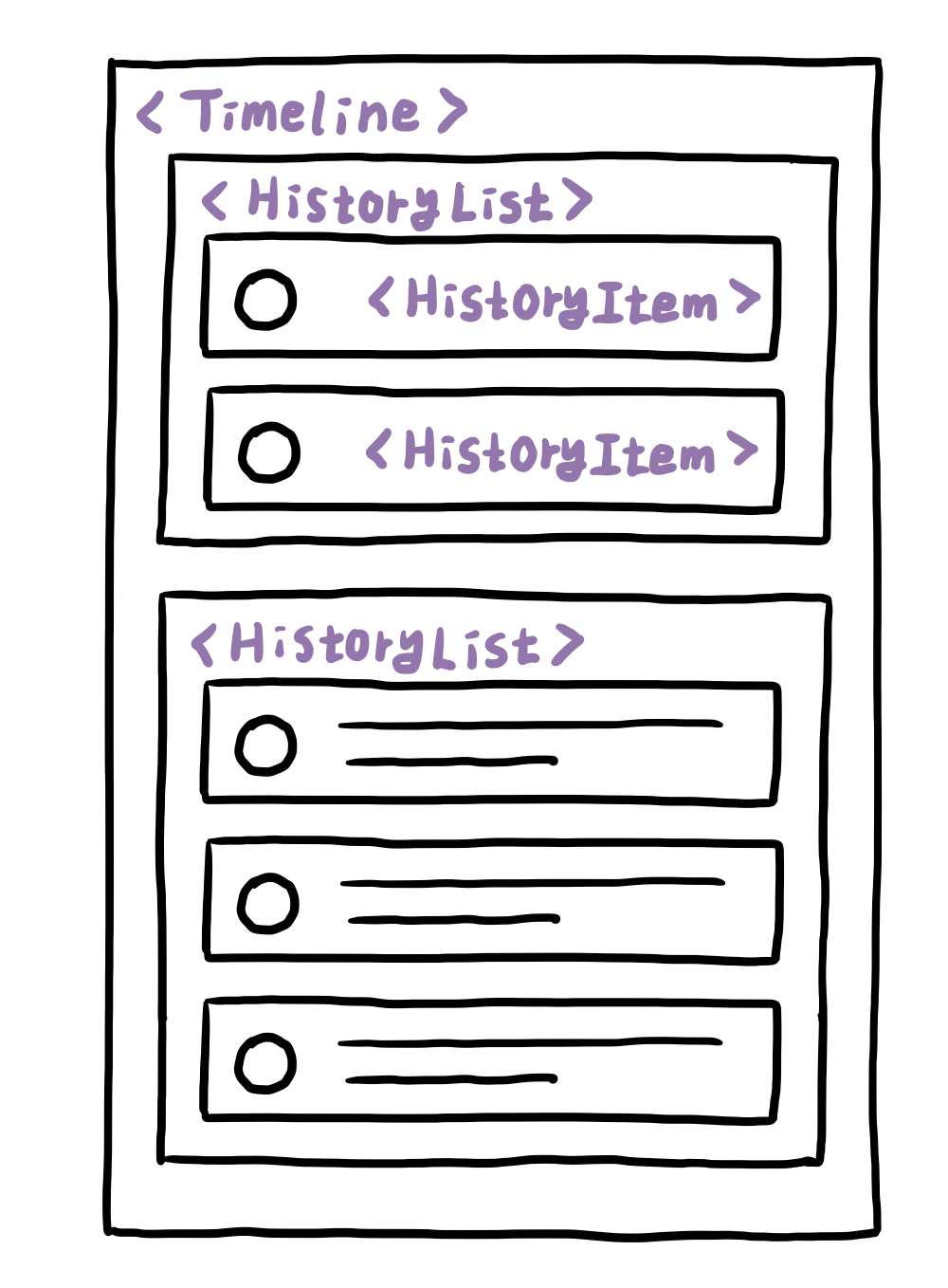
Timeline이라는 큰 틀 안에 날짜별로 분류된 HistoryList가 있고 각각의 기록들은 HistoryItem으로 나타낸다. 이 구성을 표현하기 위해서는 데이터들을 날짜별로 나눠서 재분류할 필요성이 있었다.
타임라인 로직 구성하기
일단 데이터를 어떤 방식으로 가져오는지 알아야 했기 때문에 twitter의 timeline api를 참고했다.
트위터에서는 두가지 방식으로 timeline 데이터를 가져올 수 있다. start_time과 end_time을 지정하여 해당 기간의 데이터를 전부 가져오는 방법과 max_result를 주어 정해진 개수만큼을 가져오는 방법이다.
여기에서는 max_result를 이용하여 정해진 개수만큼을 가져오는 방법으로 타임라인을 구현해볼 것이다.
max_result로 데이터를 가져온다 했을 때 궁금했던 점은 추가로 데이터를 호출시에 이전에 호출했던 데이터를 어떻게 기억했다가 그 이후부터 새로운 데이터를 가져오는지 였다.
트위터의 timeline api 응답 예시를 보면 meta데이터가 존재한다.
{
"data": [
{
"author_id": "2244994945",
"created_at": "2020-09-03T17:31:39.000Z",
"id": "1301573587187331074",
"text": "Starting today, you can see your monthly Tweet usage for the v2 API in the developer portal. ✨📊\n\nThis tracks how many Tweets you’ve received from filtered stream and recent search. Learn more here: https://t.co/nfJHkFRQcZ https://t.co/vFXmoj3qaA"
},
...
],
"includes": {
"users": [
{
"created_at": "2013-12-14T04:35:55.000Z",
"id": "2244994945",
"name": "Twitter Dev",
"username": "TwitterDev"
}
]
},
"meta": { // <- 요기✨
"newest_id": "1301573587187331074",
"next_token": "t3buvdr5pujq9g7bggsnf3ep2ha28",
"oldest_id": "1296887316556980230",
"previous_token": "t3equkmcd2zffvags2nkj0nhlrn78",
"result_count": 5
}
}meta에 들어있는 next_token은 data에 포함된 토큰의 다음 token id를 반환한다.
이 next_token값을 저장했다가, 다음 요청 때 pagination_token값으로 파라미터를 추가해서 보내면 그 요청은 pagination_token부터 max_result개수 만큼의 결과를 반환하게 된다.
api 호출 시 max_result와 pagination_token을,
response 값에는 next_token이 필요하다는 것을 알았다.
이제 직접 타임라인을 만들어보자.
임시 데이터와 UI 구현
먼저, 임시 데이터를 생성해주었다.
const data = [
{
id: 1,
user_name: '몽몽',
user_id: '11111',
created_at: dayjs().subtract(5, 'minute').format('YYYY.MM.DD HH:mm'),
text: 'Seems I`ve been dreaming for too long. I can`t find the reasons to move on.'
},
{
id: 2,
user_name: '뉴',
user_id: '33333',
created_at: dayjs().subtract(10, 'minute').format('YYYY.MM.DD HH:mm'),
text: 'hello🤪'
},
{
id: 3,
user_name: 'kk',
user_id: '44444',
created_at: dayjs().subtract(3, 'hour').format('YYYY.MM.DD HH:mm'),
text: 'This is test message.'
},
...
]
loading화면과 기본 ui를 만들어주었다.
전체적인 파일 구조는 다음과 같다.
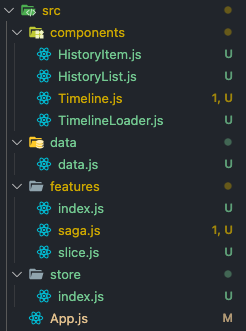
└ components // 위에서 구성한 component들이 들어있다.
└ data // 임시 데이터 파일
└ features
└ saga // redux-saga를 사용해 임시 데이터를 불러온다.
└ slice // redux slice와 selector가 들어있다.
└ store // redux 스토어
타임라인의 로직은 다음과 같을 것이다.
데이터를 일정 개수만큼 가져오기 → 가져온 데이터를 날짜별로 가공 → 화면에 출력
더보기 버튼 클릭 → 이후 지점부터 다시 일정 개수만큼 로딩 후 데이터 concat
→ 가져온 데이터를 날자별로 가공 →화면에 출력 → ...
먼저, 데이터를 일정 개수만큼 가져오는 로직을 구현해보자.
1️⃣ 데이터 일정 개수만큼 가져오기
트위터의 timeline api 등 실제 api와 호출한다면 알아서 원하는 개수만큼 데이터를 response 해주겠지만, 지금은 임시 데이터를 생성하여 사용할 것이기 때문에 일정 개수만큼 데이터를 반환하는 로직도 만들어주어야 했다. 이 로직은 엄밀히 말하면 데이터 전처리 과정이기 때문에 saga에 구현하였다.
변수명은 더 직관적으로 max_result → count , pagination_token → next_id 로 사용하였다.
// features/saga.js
export const getTimelineAction = createAction("timeline/getTimelineAction");
// count만큼 데이터 추출
function getLimitedData(data, start = 0, count){
const end = start + count;
return {data: data.slice(start, end), nextId: data.length < end ? null : end};
}
// 타임라인 가져오는 제너레이터
function* getTimelineFlow(action) {
try {
yield put(getTimelineRequest());
const response = yield call(getTimelineData);
// 임시 로직
const {count next_id} = action.payload;
const limited_result = getLimitedData(response, next_id, count);
yield put(getTimelineSuccess(limited_result));
} catch (error) {
yield put(getTimelineFailure(error));
}
}
function* rootSaga() {
yield takeLatest(getTimelineAction, getTimelineFlow);
}
export { rootSaga };
getTimelineAction을 호출할 때 count와 next_id를 payload로 넘겨주면,
const response = yield call(getTimelineData) -> 임시 데이터를 불러와 response에 넣어주고,const limited_result = getLimitedData(response, next_id, count) -> 원하는 개수만큼 재단해준다.
가장 처음 로딩했을 때 next_id는 null이기 때문에 start = 0으로 초기값을 넣어준다.
getLimitedData의 리턴 값은 { data : [ ... ], next_id : n }이다. data에는 next_id부터 count만큼의 데이터가 들어있으며, next_id에는 리턴한 가장 마지막 데이터의 id 값을 반환한다.
만약 count개수보다 남아있는 데이터의 개수가 적으면, 더 이상 추가로 불러올 데이터가 없다는 의미로 nextId에 null을 넣어준다.
2️⃣ 가져온 데이터를 날짜별로 가공
// features/slice.js
const initialState = {
loading: false,
error: null,
timelines: {
history: {}
},
nextId: null
};
const timeline = createSlice({
name: 'timeline',
initialState,
reducers: {
...
getTimelineSuccess: (state, action) => {
const { data, nextId } = action.payload;
state.loading = false;
state.timelines = groupByDay(data, state.timelines.history);
state.error = null;
state.nextId = nextId;
},
...
}
});saga를 통해 가져온 데이터는 state.timelines 에 넣기 전 날짜별로 가공해주었다.
// features/slice.js
const groupByDay = (data, histories) => {
const history = data.reduce((history, timeline) => {
const day = timeline.created_at.split(" ")[0];
if (!history[day]) history[day] = [];
history[day] = history[day].concat(timeline);
return history;
}, histories);
return {
days: Object.keys(history).sort((a, b) => dayjs(b).isBefore(a, "date")),
history,
};
};timeline.created_at에는 'YYYY.MM.DD HH:mm'형식의 데이터가 들어있기 때문에 split(" ")[0]을 통해 날짜 부분만을 추출한다. 이 날짜가 새로 생성할 객체의 key값이 된다.
이미 날짜가 존재한다면, 기존의 데이터에 합쳐준다.
history에는 새로운 객체 배열이 들어가 있고, days에는 날짜만 따로 배열로 가져와서 정렬해주었다.
객체에는 순서가 없기 때문에 days는 아래와 같이 historyList를 날짜 순으로 랜더링 할 때 사용된다.
timelines.days.map((date) => (
<HistoryList
key={date}
timeline={timelines.history[date]}
date={date}
/>
))
여기까지 잘 동작하는지 확인해보자.
// Timeline.js
useEffect(() => dispatch(getTimelineAction({ count: 7 })), [dispatch]);Timeline 컴포넌트가 처음 mount 될 때 7개의 History를 가져오도록 설정해주었다.
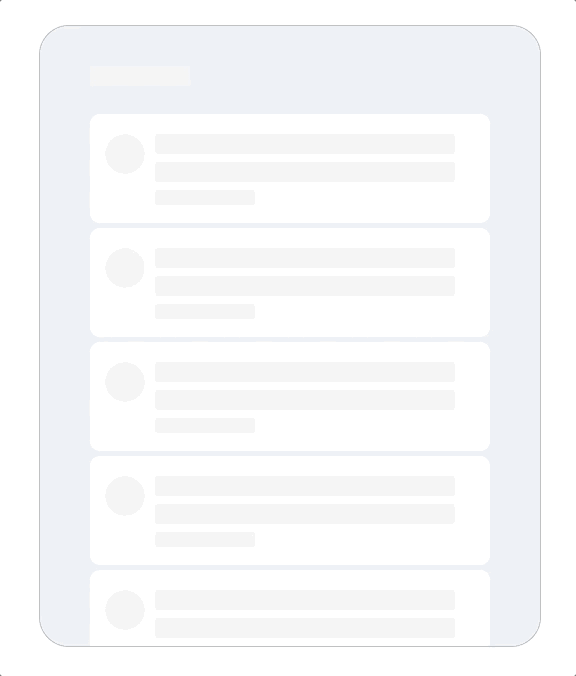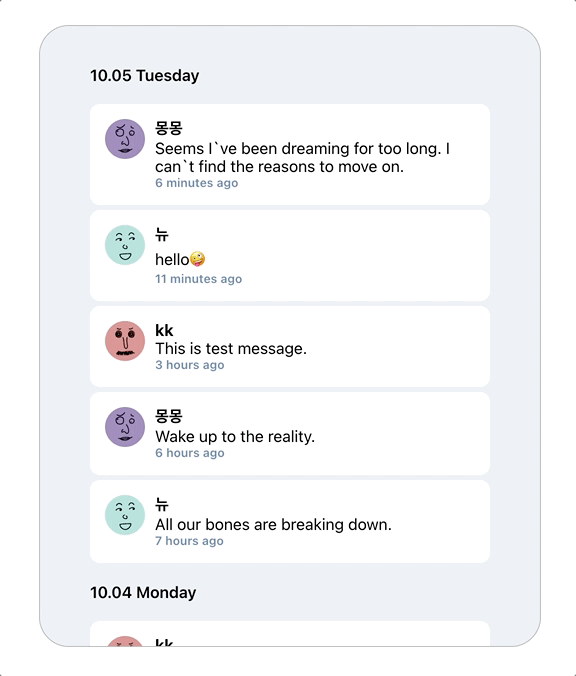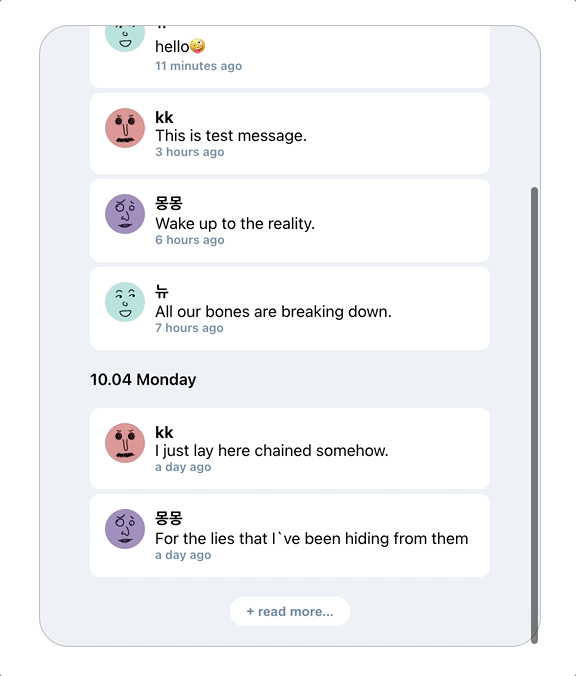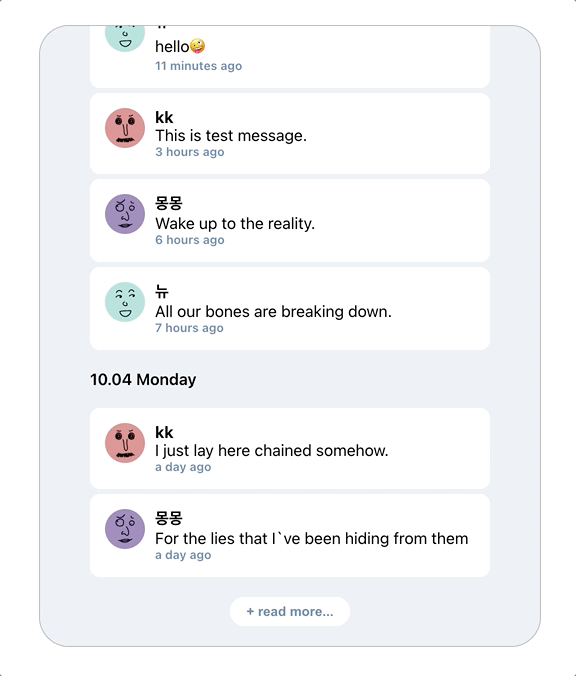
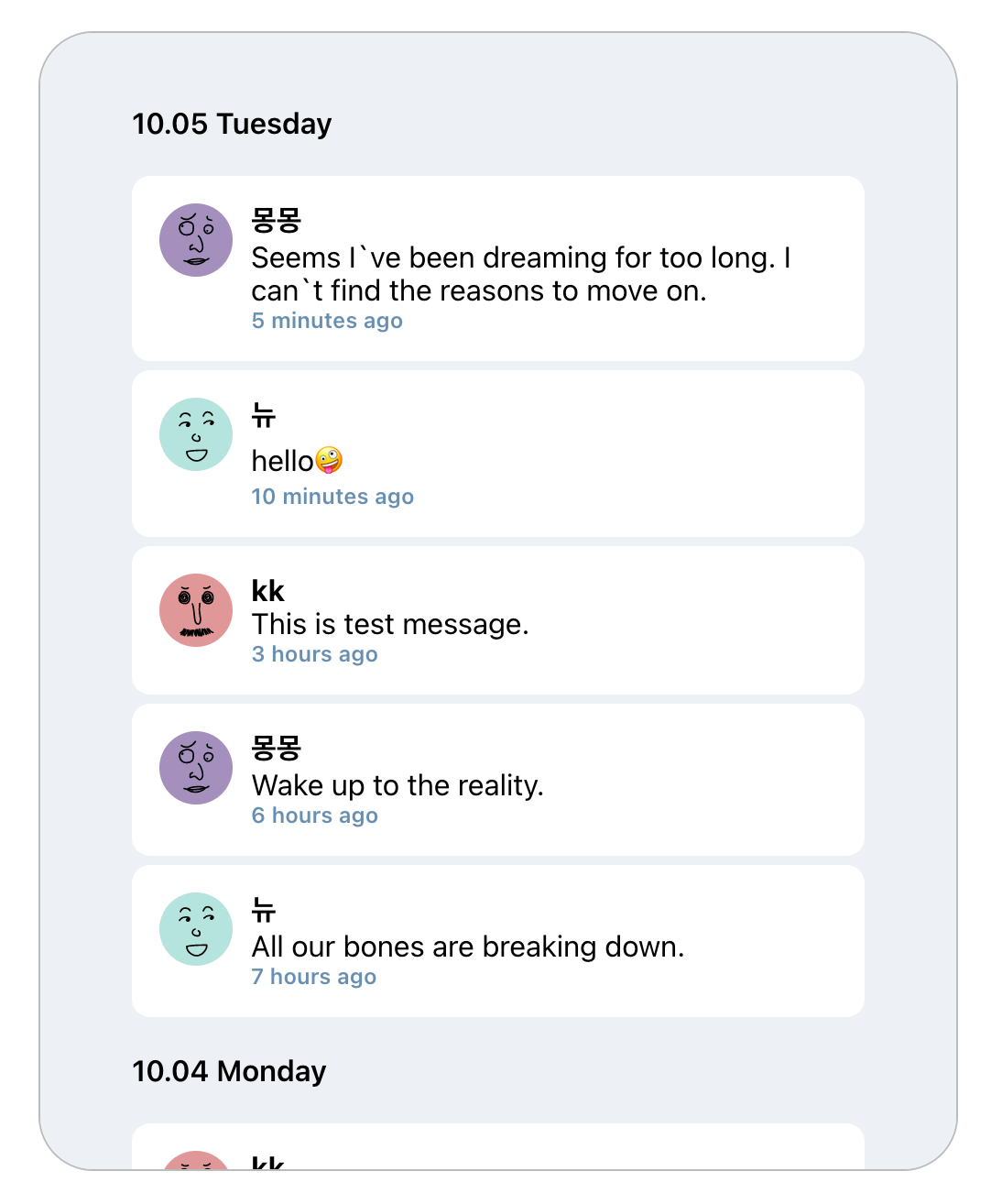
총 7개의 데이터가 제대로 로딩되는 것을 확인할 수 있다!
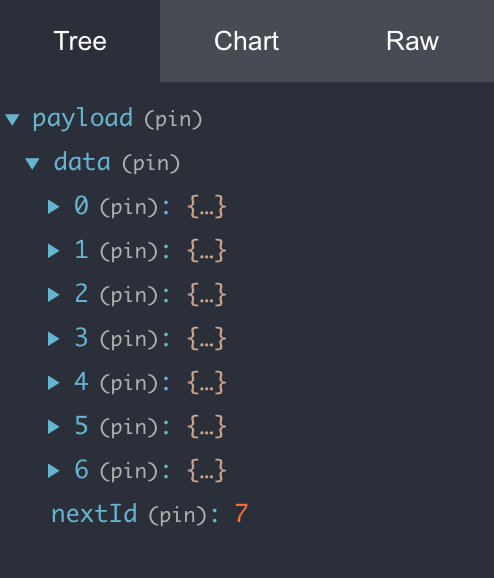
데이터 7개와, nextId까지 정상적으로 return 된 것이 보이고
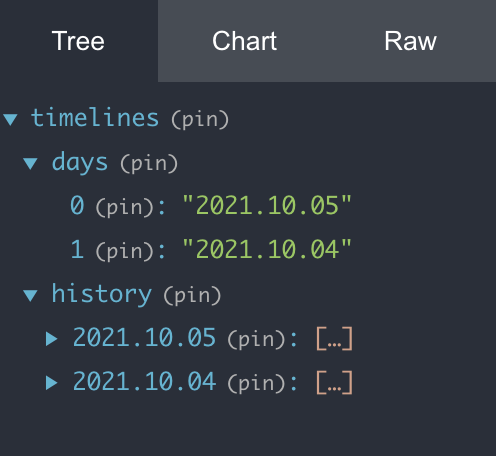
데이터가 날짜별로 잘 분류된 것을 확인할 수 있다.
이제 + read more...버튼을 누르면 추가 데이터를 로딩하는 기능을 구현해야 한다.
➕더보기 버튼 추가하기
nextId를 받아 새로운 데이터를 호출하기 위한 액션을 dispatch 하는 메서드를 만들어주었다.
// Timeline.js
const { loading, timelines, nextId } = useSelector(timelineSelector);
const getTimeline = useCallback(() => {
let params = {
count: 7,
};
if (nextId) {
params.next_id = nextId;
}
dispatch(getTimelineAction(params));
}, [dispatch, nextId]);nextId가 있을 시에는 params에 그 값을 추가한다.
// Timeline.js
// mount시
useEffect(() => {
getTimeline();
// eslint-disable-next-line react-hooks/exhaustive-deps
}, []);
// read more 버튼 클릭시
const onClick = useCallback(() => {
if (!nextId) {
alert("모든 데이터를 조회했습니다.");
} else {
getTimeline();
}
}, [nextId, getTimeline]);버튼 클릭 시마다 getTimeline()을 호출하도록 구현했다. 클릭시 nextId가 null이면 추가로 불러올 데이터가 더 이상 없다는 뜻이므로 알림메세지를 띄워주었다.
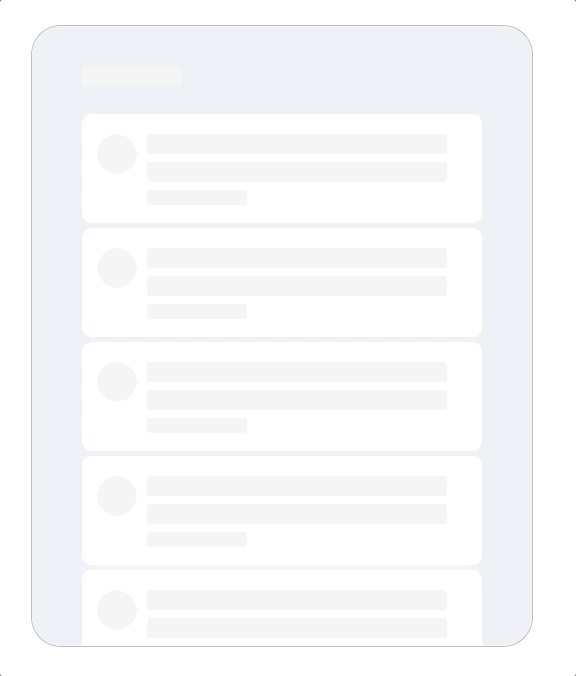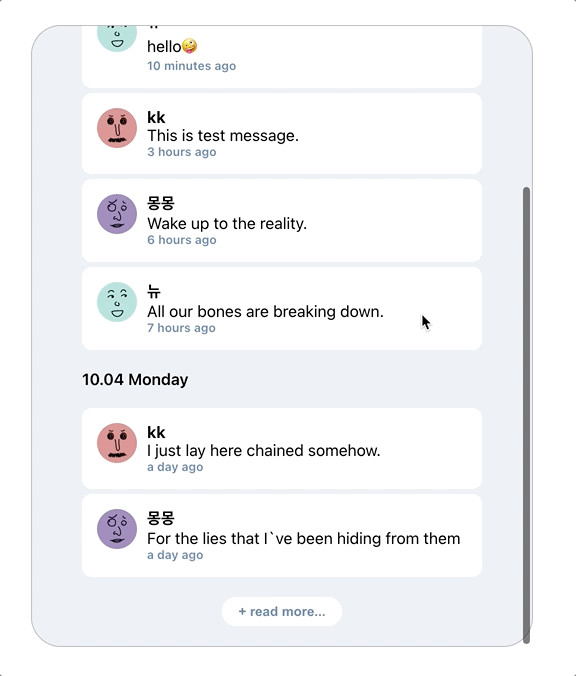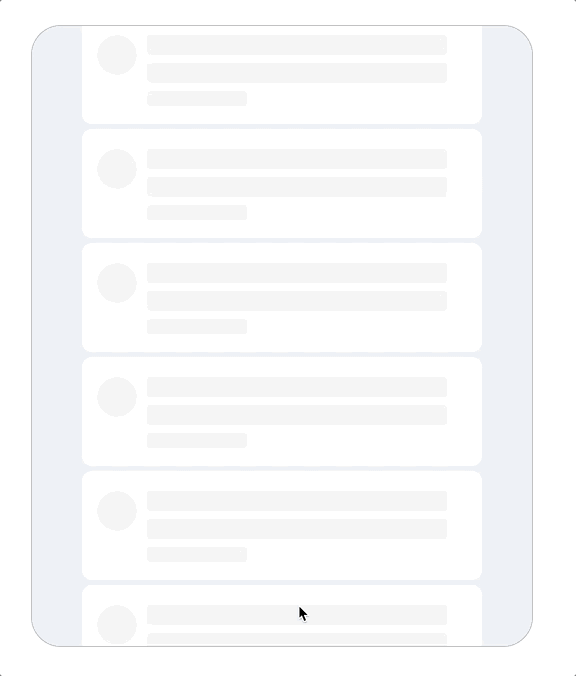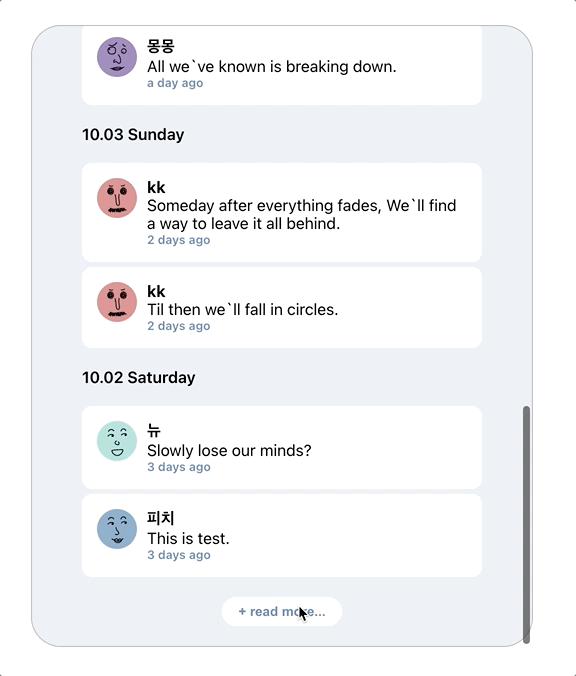
음? 뭔가 이상하다.
❗️문제점
여기서 문제점이 발생한다. 추가 목록 호출 시에도 로딩 화면이 보인다 (+ 스크롤도 처음으로 돌아간다)
function Timeline() {
const { loading, timelines, onClick } = useTimeline();
return (
<TimelineWrap>
{loading ? (
<TimelineLoader />
) : (
{timelines.days.map((date) => (
<HistoryList
key={date}
timeline={timelines.history[date]}
date={date}
/>
))}
...
)}
</TimelineWrap>
);
}loading이 true일때 로딩 화면이 보이는데, 이 로딩값을 saga에서 다루기 때문에 api 호출시에는 무조건 true → false를 거쳐가게 된다. 따라서 조건을 추가하여 추가 호출시에는 로딩화면 없이 기존 데이터에 추가되도록 코드를 변경해줘야 한다.
custom hook 만들기
이 문제를 해결하기 전, custom hook을 만들어 Timeline컴포넌트에 작성한 모든 기능 함수들을 custom hook으로 옮겨주었다.

// useTimeline.js
function useTimeline() {
const { loading, timelines, nextId } = useSelector(timelineSelector);
const dispatch = useDispatch();
// api 호출 매서드
const getTimeline = useCallback(() => {
let params = {
count: 7,
};
if (nextId) {
params.next_id = nextId;
}
dispatch(getTimelineAction(params));
}, [dispatch, nextId]);
// read more 버튼 클릭시 이벤트매서드
const onClick = useCallback(() => {
if (!nextId) {
alert("모든 데이터를 조회했습니다.");
} else {
getTimeline();
}
}, [nextId, getTimeline]);
// mount시 timeline api 호출
useEffect(() => {
getTimeline();
// eslint-disable-next-line react-hooks/exhaustive-deps
}, []);
// unmount시 timeline 리셋
useEffect(
() => () => {
dispatch(resetTimeline());
},
[dispatch]
);
return {
loading,
timelines,
onClick,
};
}
export default useTimeline;이 작업을 통해 프레젠테이션 컴포넌트와 컨테이너 컴포넌트가 완벽하게 분리되었다.
✔ 문제 해결
// useTimeline.js
function useTimeline() {
return {
loading: loading && !timelines.days.length,
timelines,
onClick,
};
}
timelines에 데이터가 존재하지 않을 때만 loading이 true가 되도록 변경해주었다.
기존 Timeline 컴포넌트는 수정하지 않아도 된다!
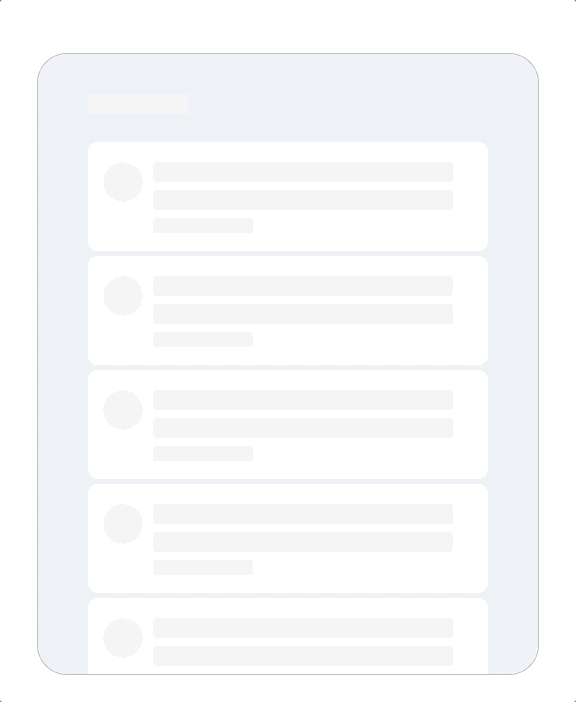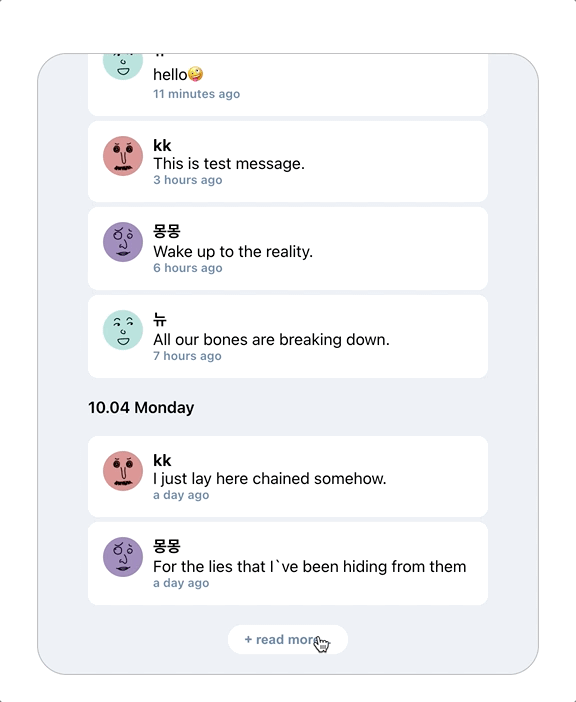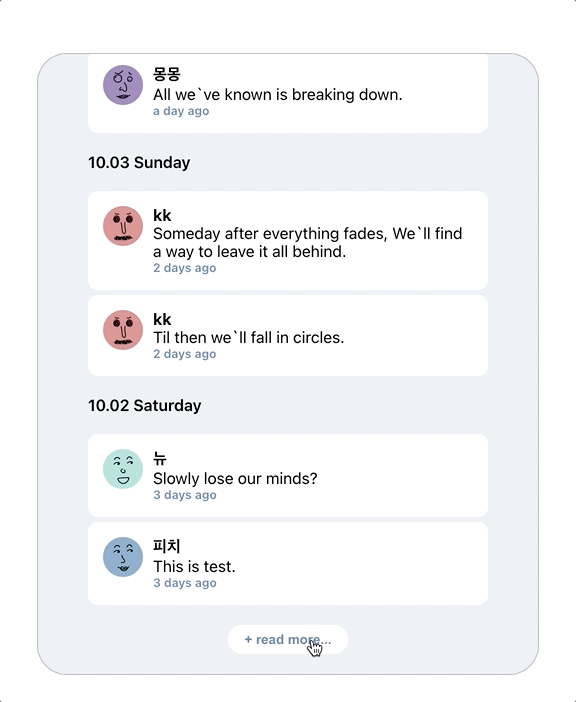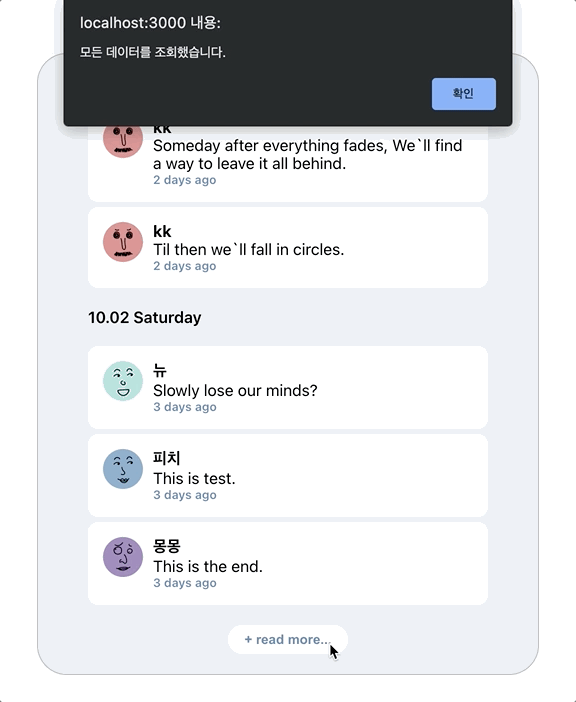
로딩 화면 없이 추가 데이터가 스크롤 위치 밑으로 생성된다.
지금은 예시로 만든 프로젝트라 alert으로 모든 데이터를 불러왔다는 것을 알렸지만, 실제 프로젝트에서는 snack bar나 + read more 버튼을 숨김으로 데이터가 끝났다는 것을 사용자에게 알려줄 수 있다.
➕
전체 코드를 확인하고 싶다면 github로